Are you new to Coding? This series of articles is a beginners’ overview of version-control, Git and GitHub.
In this article we’ll learn some of the key concepts and terminology related to Git
In part 1 of this series, we learn that GitHub is an online service for hosting your Git repositories.
In part 2 of this series, we learn some of the key concepts and terminology related to Git.
In part 3 of this series, we learn how to use GitHub to create a new empty repo.
In part 4 of this series, we install Git on our local machine and clone our new GitHub repo.
In part 5 of this series, we learn how to begin working with Git - how to commit files, how to push them to GitHub and more.
In part 6 of this series, we learn how to work with Git branches - how to create them, move between them and merge changes.
Some basic Git concepts
Before we get stuck into some practical exercises, let’s cover some of the basic ideas and terminology.
Version-control works by tracking which files in your project have been modified.
When you decide that you want to save your work, a snapshot of all of those files, with all of the changes that were made, is recorded.
- What isn’t saved, is an entire copy of every single file in your project - only the “delta” (the difference) is saved.
When you take an initial copy of a repository, this is known as “cloning”
“Cloning” means that you take files stored in a repository (in this case, hosted on GitHub) and copy them to your local computer, where you can then edit those files.
The snapshot of changes that you make is called a “commit”.
In some other systems, this is known as “checking-in”.
- As you progress your work, you can make multiple “commits” - every time you do this, a new record is added to your repository.
- Every commit has its own unique number called a “hash”
- You should assign a description or message to each commit. This helps you identify what you were working on when you come to review the change history in the future.
After you have modified files, you can pick the ones you want to commit - this is called “staging”.
- In some version-control systems, once you have changed files, you have no option but to include them all in your commit. Git is better than those systems because it gives you the option to explicitly identify which files, amongst the many you may have edited, that you wish to include in a commit.
Imagine you are working on two tasks. Having finished the first task, you move straight onto the second. Having realised that you forgot to commit the changes related to the first task, you now want to make two separate commits (because it will make the commit history and description clearer).
Staging is the solution to this problem because it allows you to cherry-pick which of the modified files that you wish to commit. This means you can stage and commit the remaining changed files later.
- You can split a copy of your work into a separate “timeline” and work on a feature, checking in your changes as usual, without breaking the main version. This alternative timeline is called a “branch”
- Git allows a project to be split up into multiple separate branches. You give a branch a name and can call it something relevant.
- It’s common in software development to have the main branch or “master” branch, store the version of the code that is used in the live/production version of your system.
- A common way of working is for a developer to create a branch from the latest version of the code. They can then work on that code, committing changes as they go, without the risk of interfering with either the master version of the code or breaking the code for everyone else. For example, by committing unfinished or untested work.
- When you are happy that your changes are in good shape, you can merge your work back into the main branch. Even though your work then becomes part of the main branch, all of your version history (commits - comments, changes, etc) are preserved in the Git history.
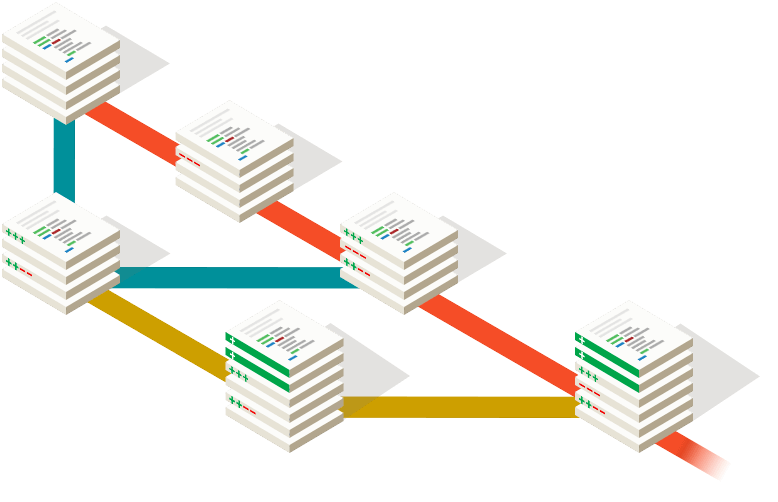
The following artwork gives you a visual idea of how branching works. In the image, the red line could represent the “master” branch. You can see how the blue and yellow versions can be separated - but can then be merged back into the red branch at a later time.
Git stores repository information on both a central server AND your local machine - this is called a “distributed” version-control system
A distributed version-control is a concept that can sometimes cause newbies a bit of confusion:
- It tracks changes centrally on the hosted repository (i.e. GitHub)
- It tracks changes on your local machine.
Imagine you’ve just boarded an aircraft with your laptop. You cloned your repo back in the airport using WiFi, but now you want to get on with work, making periodically commits as usual - but you’re offline from the internet.
With Git, you can still carry on working, even without a connection to the repository server. You can continue to edit your code, making commits which are saved locally.
Even when offline, you have a full copy of the entire version-control system, meaning that you have full access to the projects’ commit history. This applies to any history that you have only just added whilst in the air, or going all the way back to the very first version of a file.
Later, when you arrive at your destination, you can then upload the commits that you made locally, back up to the server. This will then make all of your changes available for everyone else in your team or community to see.
The term “push” means to upload the version on your local machine back up to the server.
The term “pull” means to download the latest version from the server to the version you have locally. This means that if anyone who collaborates with you on the project has made changes, you have access to their work too.
The term “merge conflict” describes the situation when two people have edited the same file at the same time.
Unlike other version-control systems, Git does not use file-locks to stop other people working on the same file at the same time. Inevitably, two or more developers will work on the same file at the same time and will lead to the problem of “which change should we use?”
Using appropriate tools, a developer can review the original, the changes that they made and the changes their colleague made. They can then choose one version instead of the other, or even cherry-pick parts from both of the new versions to create a combined or “merged” version of the file.
Git has a system that allows anybody to contribute to a project, but only if their change is approved by a project owner. This is called a “Pull Request” (it is often abbreviated to the anachronism “PR”).
With an open-source project (i.e. one that is publically visible), anybody can clone a copy of a project, work on it - and then feed their changes back to the project owner.
- A “Pull Request” is a way of saying to the project owner : “Hi, I’ve made some changes - would you look at them please - and if you’re happy, merge them into the repository”.
The following video, produced by GitHub, is a really helpful introduction:
Next, in part 3 of this series, we’ll create a GitHub account and your first repository.
PREVIOUS : Read part 1 : Overview of version-control and Git